Introduction about Qualitative Research
Qualitative research is invaluable for generating rich, contextual insights from data such as interview transcripts and think-aloud sessions. However, this richness is a double-edged sword: the data often contains sensitive Personally Identifiable Information (PII) and identity cues that can unintentionally introduce bias into the analysis.
This case study documents a methodological enhancement to a complex qualitative analysis project. The project was ambitious, leveraging the strengths of Large Language Model (LLM) for scalable thematic analysis an approach inspired by the ATA-LLM: Human-AI Collaboration in Thematic Analysis framework developed by Professors Jesus A. Beltran, Lizbeth Escobedo, and Franceli Cibrian.
We utilized HRIDA AI's Spro as a core for data-sanitization and for security layer before conducting an inductive, grounded-theory-based qualitative analysis. The goal is to demonstrate why data sanitization is not just an ethical requirement, but a methodological necessity that materially improved the rigor, neutrality, and analytic quality of the research outcomes.
Overview about Dataset
This case study is about researching students' information choices (RSIC) dataset of 30 graduate student think-aloud transcripts from the Qualitative Data Repository (QDR), focused on online search behavior and credibility assessment. This dataset examines how students choose and evaluate online information when starting a science-related research task. It focuses on how students judge the credibility, usefulness, and type of sources they see in search results, like a Google search results. The study includes students from elementary school through graduate level and captures their real-time thinking using questionnaires, interviews, simulated search tasks, and think-aloud sessions. Overall, the dataset contains think-aloud transcripts, providing insight into students' information-seeking behavior and how it differs across education levels.
ATA-LLM: Human-AI Collaboration in Thematic Analysis framework
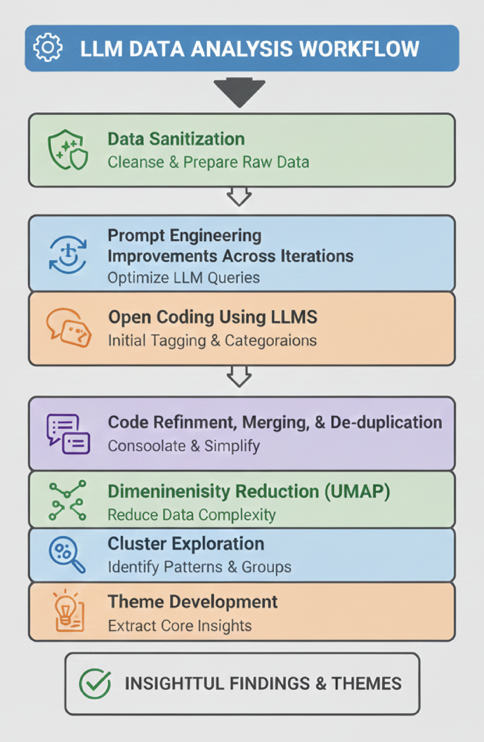
Figure 1: This image explains the steps followed in qualitative analysis using LLMs.
Figure 1 illustrates the complete ATA LLM framework used for qualitative analysis, showing how raw textual data is systematically transformed into meaningful insights. The process begins with Data Sanitization, where raw qualitative inputs such as interview transcripts, survey responses, or open-ended feedback are cleaned and prepared. This step removes personal and irrelevant information to ensure the analysis focuses only on meaningful content. Clean data is essential because even advanced AI models can amplify bias and errors if the input contains personal or sensitive information.
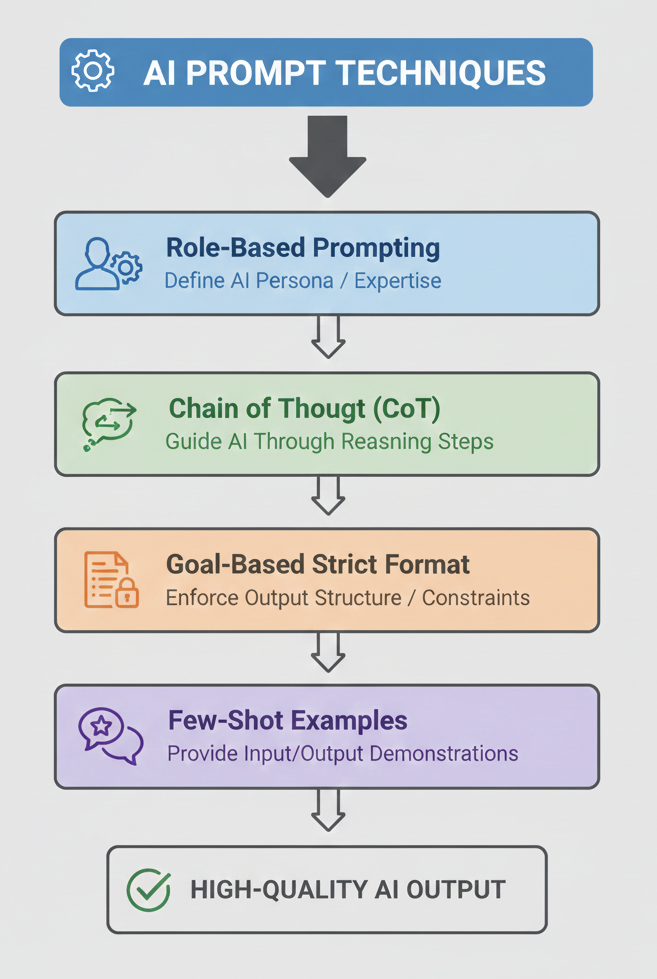
Figure 2 This image illustrates various prompt engineering techniques for qualitative research
Once the data is prepared, the workflow moves into Prompt Engineering, which guides how the LLM analyzes the qualitative data. Instead of using generic prompts, the prompts were carefully crafted to reflect a human qualitative research process. This begins with role-based prompting, where the AI is instructed to act as a qualitative researcher. Chain-of-thought guidance then leads the model to analyze the text step by step understanding the content before forming open codes. Clear goals and structured instructions ensure consistency in how codes are created, while few-shot examples demonstrate how responses should be coded. Together, these strategies help produce richer, more consistent qualitative insights, as shown in Figure 2.
Following prompt optimization, Open Coding Using LLMs is performed. At this stage, the AI reads through the qualitative data and assigns descriptive labels (codes) to meaningful segments of text. These codes are not predefined; instead, they emerge from the data itself. Importantly, annotations help reduce individual bias by allowing consistent comparison across multiple data points rather than relying on subjective interpretation alone.
After initial coding, Code Refinement, Merging, and De-duplication consolidates similar or overlapping codes. This step simplifies the analysis by ensuring that multiple labels expressing the same idea are combined into a single, coherent concept. The result is a cleaner and more reliable coding framework that better reflects the underlying meanings in the data.
To further support pattern discovery, Dimensionality Reduction (UMAP) is applied. This step reduces the complexity of high-dimensional textual representations while preserving meaningful relationships. In simple terms, it helps compress large amounts of coded information into a form that is easier to explore and visualize. This makes it possible to identify natural groupings within the data.
Next, Cluster Exploration groups similar codes or responses together. These clusters reveal shared experiences, concerns, or perspectives across participants. Instead of analyzing responses individually, clustering allows researchers to see how ideas relate to each other at scale.
Finally, Theme Development synthesizes these clusters into higher-level themes. Themes represent the core narratives or insights emerging from the data. The process concludes with Insightful Findings and Themes, which are clear, interpretable outcomes that can inform decisions, research conclusions, or policy recommendations.
Balancing Personal Information Redaction and Research Context
This case study involves a qualitative analysis of transcripts from the Researching Students' Information Choices (RSIC) dataset link. These transcripts detailed participants' online research processes and were inherently laden with both sensitive PII (names, affiliations) and crucial contextual data (the specific names of search platforms, like "YouTube" or "Wikipedia").
In qualitative research, it is important to carefully balance the removal of personal information with preserving the core purpose of the study. Since qualitative analysis relies on extracting meaning and insights from text, excessive redaction can remove essential context and reduce the value of the data for analysis, especially when using LLMs. In this dataset, only personal identifiers such as individual names and organization names were redacted to minimize potential bias and protect privacy. However, widely known platforms like YouTube or Wikipedia were not redacted because they are crucial for understanding how students evaluate source credibility. This approach ensures that the data remains ethically sound while still providing sufficient context for meaningful qualitative analysis by LLMs.
Using the raw text from the dataset directly for a high-rigor and LLM analysis created three distinct risks:
| Risk Category | Description | Strategic Impact |
|---|---|---|
| Ethical/Legal Risk | Transcripts contained highly sensitive PII that required permanent, auditable redaction to ensure participant anonymity and legal compliance. | Mitigate PII Leakage |
| Methodological Risk | Traditional redaction could destroy crucial analytical data (e.g., mention of "Wikipedia"), leading to Over-sanitization and loss of analytical depth. | Preserve Research context |
| Security Risk | Utilizing a high-speed, third-party LLM inference service (Groq) required a robust security and compliance layer to guarantee sensitive data remained secure in transit. | Ensure Compliance & Security |
The Critical Problem: The Double-Edged Sword of Bias
Unsanitized data poses a risk to both human and AI analysis:
1. Human Bias (The Halo Effect)
When a human coder sees an identifiable name, a specific institution, or a precise geographic location, their existing knowledge about that entity can unconsciously influence their interpretation. For example, knowing a participant is from a high-profile university might subconsciously lead a coder to interpret their comments on "credibility" differently. This is Interpretation Bias.
2. LLM Bias (Confirmation and Contextual Leakage)
LLMs are trained on massive public datasets. Unredacted PII (a specific name or location) can trigger the LLM's vast training data to associate that identifier with a demographic profile or attribute, leading to Skewed Code Generation (e.g., confirmation bias).
Furthermore, PII is irrelevant to the research question and acts as Noise, causing the LLM to generate irrelevant labels (e.g., "Labeled 'gratitude expression' to the sentence 'Thank you'").
The core challenge was to achieve a delicate balance: Mitigate Bias from Under-sanitization (PII Leakage) while simultaneously preventing Loss of Analytical Value from Over-sanitization (Context Removal). A simple search-and-replace tool was inadequate for this task.
The Solution:
Entity-Specific Data Sanitization with HRIDA AI's Spro
HRIDA AI's Spro was selected for its sophisticated text-based data sanitization and redaction capabilities, which provided the necessary control to navigate the "under-sanitization vs. over-sanitization" dilemma. Its key differentiator was Entity-Specific Redaction. It allowed us to define precisely which categories of entities to mask, providing full control over the sanitization boundary.

Figure 3 This Image shows the entities present in the spro, provide absolute control over data sanitization.
Key HRIDA AI's Spro Features for Data Sanitation and Their Impact:
| HRIDA AI's Spro Feature | Application in RSIC Project | Impact on Qualitative Analysis Rigor |
|---|---|---|
| Controlled PII Entity Detection | Configured to target only "Human Names," "Email Addresses," and "Addresses," while explicitly ignoring common nouns. | Precision Sanitization: Successfully eliminated all direct PII (e.g., Gladwin Irudayaraj replaced with [PARTICIPANT 01]) while preserving essential analytical entities like Wikipedia and YouTube. |
| Consistent Pseudonym Generation | Replaced all detected PII with consistent, traceable pseudonyms (e.g., [PARTICIPANT 01]). | Maintained Research context: Preserved the narrative flow for Axial Coding, allowing researchers to track an individual's journey without their personal identity influencing interpretation. |
| Automated Audit Log | Generated a secure log of only the PII that was modified. | Ethical & Methodological Verification: Provided a clear, transparent record to demonstrate ethical compliance and verify that non-PII terms were correctly untouched, ensuring the data was fit for purpose. |

Figure 4 This image shows the logs of all inputs and outputs enter through Spro proxy and alert message from Spro
Enabling Secure LLM Inference through HRIDA AI's Spro Proxy
The methodology adopted a cutting-edge LLM pipeline, which involved the Qwen/Qwen3-Embedding-0.6B for embedding and the GROQ API for lightning-fast inference using the Qwen/Qwen3-32B model. The reliance on a high-speed, third-party service like OpenAI, Claude, Groq or Together AI introduced a significant security challenge for sensitive academic data.
HRIDA AI's Spro's Secure Proxy Feature (Spro Proxy)
HRIDA AI's Spro provided an essential security and compliance layer by routing all calls to the third-party inference service (Groq) through its Spro Proxy.

Figure 5 This image shows the proxy provided in Spro and the project URL used for audit logs.
Key HRIDA AI's Spro Proxy Features and Their Impact:
| HRIDA AI's Spro Feature | Strategic Impact on Security and Research Context for LLM |
|---|---|
| Secure LLM Proxy | Data Leakage Prevention: Ensured that the data was protected in transit to the external LLM provider, mitigating the risk of data exposure. |
| PII/Compliance Monitoring | Uncompromising Compliance: Active monitoring and logging of every piece of personal information and data policy flag that passed through the proxy. |
This assurance allowed the research team to confidently leverage the fastest available
Inference platform (Groq) for scalability without sacrificing the highest standards of data security and academic compliance required for sensitive graduate student data.
Results: A Foundation for Unbiased and High-Quality Qualitative Analysis
The entity-specific sanitization and secure proxy provided by HRIDA AI's Spro directly led to a more rigorous and trustworthy analysis:
-
Elimination of Researcher Bias: By exclusively redacting PII, both human coders performing Open Coding and the subsequent LLM analysis were forced to focus solely on the thematic content of the search process and credibility judgments, effectively mitigating the "Halo Effect" and other forms of interpretation bias.
-
Preservation of Analytical Depth: The retention of critical terms like "Wikipedia" and "YouTube" allowed the coding process to accurately capture core themes such as "Preference for Open-Source Information" and "Use of Video Platforms," which are central to the research's theoretical foundation.
-
Enhanced LLM Efficiency and Quality: The clean, focused, PII-free dataset enabled highly refined prompt engineering. This significantly reduced the LLM's tendency to "label everything" and instead produced a manageable, focused set of codes that served as a superior, high-quality "helper" in the human-in-the-loop qualitative analysis process.
-
Enabled High-Performance AI: The secure proxy allowed for the seamless and compliant integration of Groq's high-speed inference, making the LLM collaboration scalable and efficient.
Conclusion
The successful execution of this mixed-methods qualitative study combining human expertise with high-speed LLM analysis was fundamentally enabled and safeguarded by HRIDA AI's Spro (Spro). The product delivered a secure platform that:
-
Guaranteed Ethical Compliance by providing granular, auditable control over PII redaction and compliance audit.
-
Maximized Research Context by preserving critical analytical entities, leading to more robust theoretical codes.
-
Enabled High-Performance AI by securely proxying data to the fastest LLM inference platform (GROQ), with continuous security and compliance logging.
This holistic approach resulted in a more rigorous, verifiable, and scalable qualitative analysis, significantly improving the quality of the final theoretical results compared to traditional, manual-only methods.